



PHASE
01
Documentation.
Record professional trainers on Quest 3. Hands, body, and head saved as 3D motion, labelled with the Amharic and English word.
in progress
PHASE 01 ›
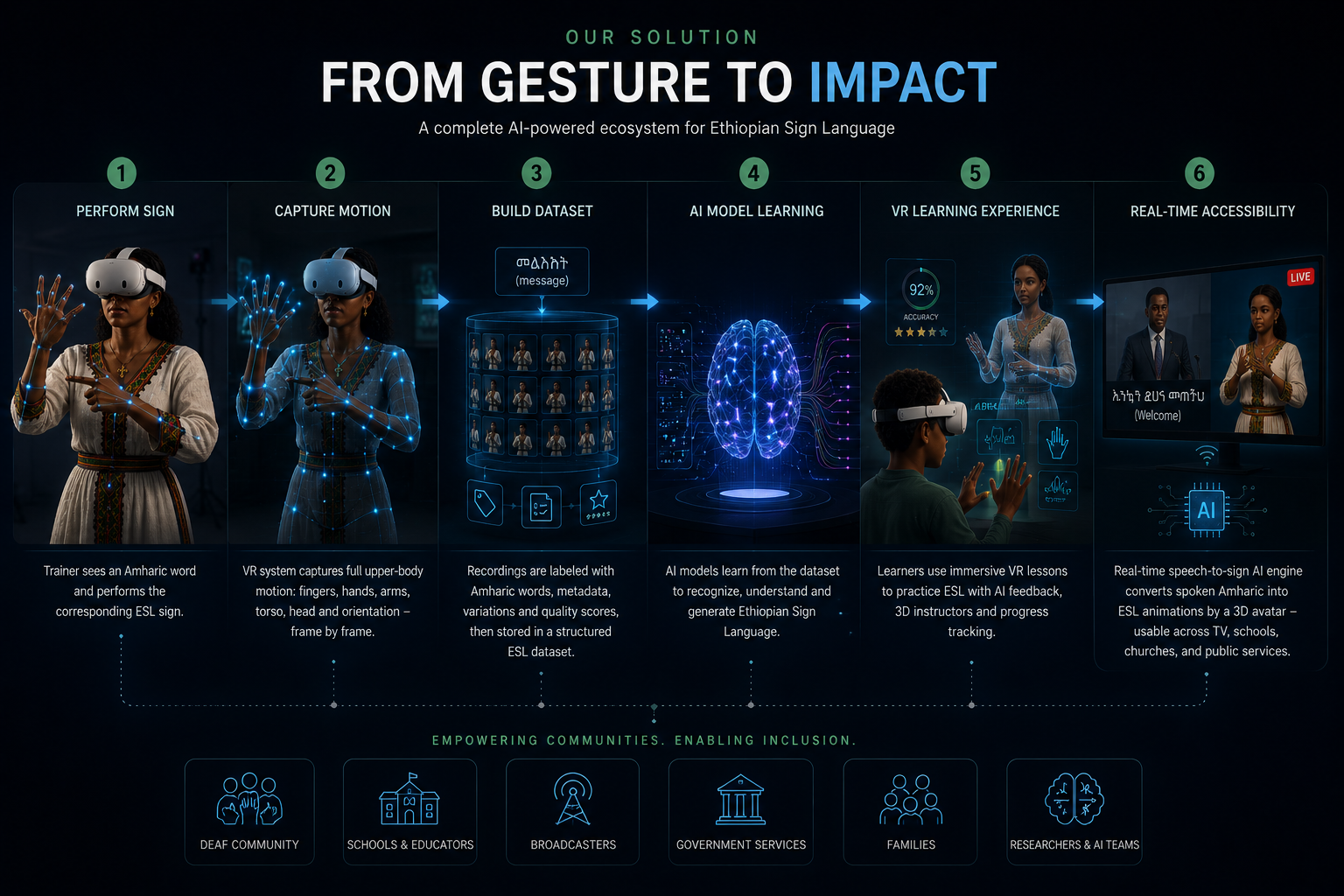
We capture ESL on Meta Quest 3 — every finger, every shift of the shoulder — with the people who actually speak it.
Open source — built in the open so deaf communities, researchers, and Unity developers can shape how a language is documented.
ESL has been left out of the digital world — no dataset, no tools, no AI that can read it. We start with documentation, because nothing else can be built without it.
Record professional trainers on Quest 3. Hands, body, and head saved as 3D motion, labelled with the Amharic and English word.
The dataset becomes a classroom. A VR room, a 3D instructor, practice sessions, AI-assisted feedback on the learner's own signs.
A 3D AI avatar that converts spoken Amharic into sign language live — for broadcasts, classrooms, and public services.
Built in Unity with the Meta XR SDK and Movement SDK. Runs entirely on the headset.
A single recording is not a language. Every word is captured many times, by many trainers — variations in hand size, signing speed, and regional style become features, not noise. AI does the rest: aligning, cleaning, clustering, and labelling each frame so the dataset can teach a model what a sign is.
Each word: multiple trainers · multiple takes · multiple speeds. Coverage across dialects and signing styles.
ML models segment the steady portion, align takes onto a common timeline, cluster variants, and write per-frame labels. Humans review the edge cases.
The dataset ships with a clean, reproducible signing of each word — plus its full variant library. Ready for a VR classroom, ready for a model to learn from.
Once we can recognise signs in 3D, we can generate them too. A speech-to-sign model takes spoken Amharic, predicts the sequence of canonical signs, and drives a 3D avatar in real time — overlaid on a TV broadcast, in a classroom, or on a phone.
Building the Unity capture app on Meta Quest 3: hand and upper-body tracking, word-prompt flow, steady-state detection, labelled clip storage. This is the foundation everything else records onto.
Bring professional ESL trainers into the loop. Refine the capture experience with them, settle the consent and pay model.
Record the everyday vocabulary — many takes per word, across multiple trainers. Daily verbs, family terms, religious and civic vocabulary.
Cleaning, alignment, clustering, and labelling at scale. First public sample release under an open license.
A learner enters a virtual room with a 3D instructor, practises signs, and gets AI feedback on their own hand pose.
Speech-to-sign in real time. A 3D avatar that converts spoken Amharic into ESL on TV, in classrooms, and in public services.
Help us capture signs. Sessions are paid and flexible.
Get in touchWe'll release dataset samples and tools under an open license.
Follow alongWe are seeking partners for Phase 2.
Let's talk